搜索到
368
篇与
的结果
-
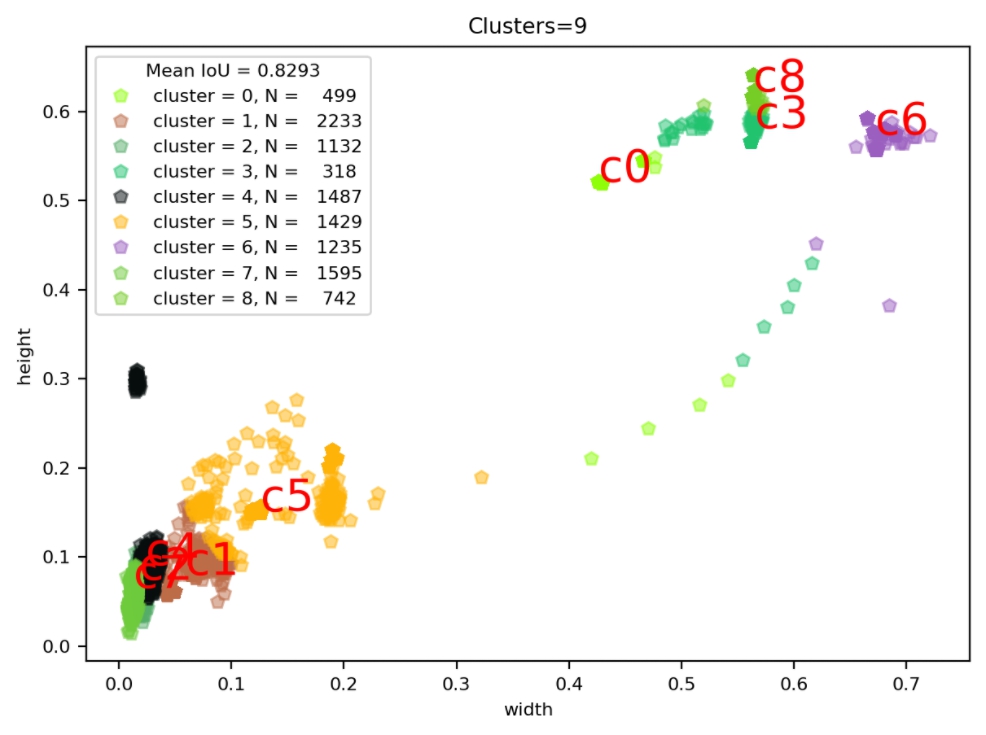
 VOC数据集的Anchor聚类--Kmeans算法实现 1.K-means算法具体介绍参考:Kmeans算法简介k-means聚类的算法运行过程:(1)选择k个初始聚类中心 (2)计算每个对象与这k个中心各自的距离,按照最小距离原则分配到最邻近聚类 (3)使用每个聚类中的样本均值作为新的聚类中心 (4)重复步骤(2)和(3)直到聚类中心不再变化 (5)结束,得到k个聚类2.算法实现2.1数据加载函数封装# STEP1:加载数据集,获取所有box的width、height import os from progressbar import * import xmltodict import numpy as np def load_dataset(data_root): xml_dir= os.path.join(data_root,"Annotations") #xml文件路径(Annotations) width_height_list = [] #用于存储统计结果 #进度条功能 widgets = ['box width_height 统计: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=len(os.listdir(xml_dir))).start() count = 0 for xml_file in os.listdir(xml_dir): # 拼接xml文件的path xml_file_path = os.path.join(xml_dir,xml_file) # 读取xml文件到字符串 with open(xml_file_path) as f: xml_str = f.read() # xml字符串转为字典 xml_dic = xmltodict.parse(xml_str) # 获取图片的width、height img_width = float(xml_dic["annotation"]["size"]["width"]) img_height = float(xml_dic["annotation"]["size"]["height"]) # 获取xml文件中的所有objects obj_list = [] objects = xml_dic["annotation"]["object"] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: obj_list.append(obj) else: # xml文件中包含1个object obj_list.append(objects) #print(obj_list) # width_height布统计 for obj in obj_list: #box 的height\width归一化 box_width = (float(obj['bndbox']["xmax"]) - float(obj['bndbox']["xmin"]))/img_width box_height = (float(obj['bndbox']["ymax"]) - float(obj['bndbox']["ymin"]))/img_height width_height_list.append([box_width,box_height]) #更新进度条 count += 1 pbar.update(count) #释放进度条 pbar.finish()调用效果#输出统计结果信息 data_root = "/data/jupiter/project/dataset/209_VOC_new" width_height_list = load_dataset(data_root) width_height_np = np.array(width_height_list) print("clustering feature data is ready. shape = (N object, width and height) = {}".format(width_height_np.shape))box width_height 统计: 100% |###############| Elapsed Time: 0:00:35 Time: 0:00:35 clustering feature data is ready. shape = (N object, width and height) = (10670, 2)2.2 将未聚类前的统计结果绘图表示# 将未聚类前的统计结果绘图表示 import matplotlib.pyplot as plt plt.figure(figsize=(10,10)) plt.scatter(width_height_np[:,0],width_height_np[:,1],alpha=0.3) plt.title("Clusters",fontsize=20) plt.xlabel("normalized width",fontsize=20) plt.ylabel("normalized height",fontsize=20) plt.show()调用效果2.3 实现距离评估函数(这里用的是iou)这里iou的计算公式为:$$ \begin{array}{rl} IoU &= \frac{\textrm{intersection} }{ \textrm{union} - \textrm{intersection} }\\ \textrm{intersection} &= Min(w_1,w_2) Min(h_1,h_2)\\ \textrm{union} & = w_1 h_1 + w_2 h_2 \end{array} $$图示代码实现import numpy as np # 数据间距离评估函数 def iou(box, clusters): """ 计算一个ground truth边界盒和k个先验框(Anchor)的交并比(IOU)值。 参数box: 元组或者数据,代表ground truth的长宽。 参数clusters: 形如(k,2)的numpy数组,其中k是聚类Anchor框的个数 返回:ground truth和每个Anchor框的交并比。 """ x = np.minimum(clusters[:, 0], box[0]) y = np.minimum(clusters[:, 1], box[1]) if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0: raise ValueError("Box has no area") intersection = x * y box_area = box[0] * box[1] cluster_area = clusters[:, 0] * clusters[:, 1] iou_ = intersection / (box_area + cluster_area - intersection) return iou_2.4实现kmeans聚类函数# 实现kmeans聚类函数 def kmeans(boxes, k): """ 利用IOU值进行K-means聚类 参数boxes: 形状为(r, 2)的ground truth框,其中r是ground truth的个数 参数k: Anchor的个数 返回值:形状为(k, 2)的k个Anchor框 """ # 即是上面提到的r rows = boxes.shape[0] # 距离数组,计算每个ground truth和k个Anchor的距离 distances = np.empty((rows, k)) # 上一次每个ground truth"距离"最近的Anchor索引 last_clusters = np.zeros((rows,)) # 设置随机数种子 np.random.seed() # 初始化聚类中心,k个簇,从r个ground truth随机选k个 clusters = boxes[np.random.choice(rows, k, replace=False)] # 开始聚类 while True: # 计算每个ground truth和k个Anchor的距离,用1-IOU(box,anchor)来计算 for row in range(rows): distances[row] = 1 - iou(boxes[row], clusters) # 对每个ground truth,选取距离最小的那个Anchor,并存下索引 nearest_clusters = np.argmin(distances, axis=1) # 如果当前每个ground truth"距离"最近的Anchor索引和上一次一样,聚类结束 if (last_clusters == nearest_clusters).all(): break # 更新簇中心为簇里面所有的ground truth框的均值 for cluster in range(k): clusters[cluster] = np.median(boxes[nearest_clusters == cluster], axis=0) # 更新每个ground truth"距离"最近的Anchor索引 last_clusters = nearest_clusters return clusters,nearest_clusters2.4 调用测试CLUSTERS = 9 #聚类数量,anchor数量 INPUTDIM = 416 #输入网络大小 clusters_center_list,nearest_clusters = kmeans(width_height_np, k=CLUSTERS) clusters_center_list_handle = np.array(clusters_center_list)*INPUTDIM # 得到最终填入YOLOv3 的cfg文件中的anchor print('Boxes:') print(clusters_center_list_handle.astype(np.int32)) Boxes: [[ 9 37] [235 239] [ 4 30] [ 24 33] [ 5 21] [ 52 63] [ 5 26] [ 7 28] [ 6 33]]2.5聚类结果绘制与效果评估(mean_iou)查看数据聚类结果import seaborn as sns current_palette = list(sns.xkcd_rgb.values()) def plot_cluster_result(plt,clusters,nearest_clusters,mean_iou,width_height_np,k): for icluster in np.unique(nearest_clusters): pick = nearest_clusters==icluster c = current_palette[icluster] plt.rc('font', size=8) plt.plot(width_height_np[pick,0],width_height_np[pick,1],"p", color=c, alpha=0.5,label="cluster = {}, N = {:6.0f}".format(icluster,np.sum(pick))) plt.text(clusters[icluster,0], clusters[icluster,1], "c{}".format(icluster), fontsize=20,color="red") plt.title("Clusters=%d" %k) plt.xlabel("width") plt.ylabel("height") plt.legend(title="Mean IoU = {:5.4f}".format(mean_iou)) # achor结果评估 def avg_iou(boxes, clusters): """ 计算一个ground truth和k个Anchor的交并比的均值。 """ return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])]) figsize = (7,5) plt.figure(figsize=figsize) mean_iou = avg_iou(width_height_np, out) plot_cluster_result(plt,clusters_center_list,nearest_clusters,mean_iou,width_height_np,k=CLUSTERS)运行效果查看聚类中心分布w = width_height_np[:, 0].tolist() h = width_height_np[:, 1].tolist() centroid_w=clusters_center_list[:,0].tolist() centroid_h=clusters_center_list[:,1].tolist() plt.figure(dpi=200) plt.title("kmeans") plt.scatter(w, h, s=10, color='b') plt.scatter(centroid_w,centroid_h,s=10,color='r') plt.show()运行效果3.汇总简略版#coding=utf-8 import xml.etree.ElementTree as ET import numpy as np import glob def iou(box, clusters): """ 计算一个ground truth边界盒和k个先验框(Anchor)的交并比(IOU)值。 参数box: 元组或者数据,代表ground truth的长宽。 参数clusters: 形如(k,2)的numpy数组,其中k是聚类Anchor框的个数 返回:ground truth和每个Anchor框的交并比。 """ x = np.minimum(clusters[:, 0], box[0]) y = np.minimum(clusters[:, 1], box[1]) if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0: raise ValueError("Box has no area") intersection = x * y box_area = box[0] * box[1] cluster_area = clusters[:, 0] * clusters[:, 1] iou_ = intersection / (box_area + cluster_area - intersection) return iou_ def avg_iou(boxes, clusters): """ 计算一个ground truth和k个Anchor的交并比的均值。 """ return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])]) def kmeans(boxes, k): """ 利用IOU值进行K-means聚类 参数boxes: 形状为(r, 2)的ground truth框,其中r是ground truth的个数 参数k: Anchor的个数 参数dist: 距离函数 返回值:形状为(k, 2)的k个Anchor框 """ # 即是上面提到的r rows = boxes.shape[0] # 距离数组,计算每个ground truth和k个Anchor的距离 distances = np.empty((rows, k)) # 上一次每个ground truth"距离"最近的Anchor索引 last_clusters = np.zeros((rows,)) # 设置随机数种子 np.random.seed() # 初始化聚类中心,k个簇,从r个ground truth随机选k个 clusters = boxes[np.random.choice(rows, k, replace=False)] # 开始聚类 while True: # 计算每个ground truth和k个Anchor的距离,用1-IOU(box,anchor)来计算 for row in range(rows): distances[row] = 1 - iou(boxes[row], clusters) # 对每个ground truth,选取距离最小的那个Anchor,并存下索引 nearest_clusters = np.argmin(distances, axis=1) # 如果当前每个ground truth"距离"最近的Anchor索引和上一次一样,聚类结束 if (last_clusters == nearest_clusters).all(): break # 更新簇中心为簇里面所有的ground truth框的均值 for cluster in range(k): clusters[cluster] = np.median(boxes[nearest_clusters == cluster], axis=0) # 更新每个ground truth"距离"最近的Anchor索引 last_clusters = nearest_clusters return clusters # 加载自己的数据集,只需要所有labelimg标注出来的xml文件即可 def load_dataset(path): dataset = [] for xml_file in glob.glob("{}/*xml".format(path)): tree = ET.parse(xml_file) # 图片高度 height = int(tree.findtext("./size/height")) # 图片宽度 width = int(tree.findtext("./size/width")) for obj in tree.iter("object"): # 偏移量 xmin = int(obj.findtext("bndbox/xmin")) / width ymin = int(obj.findtext("bndbox/ymin")) / height xmax = int(obj.findtext("bndbox/xmax")) / width ymax = int(obj.findtext("bndbox/ymax")) / height xmin = np.float64(xmin) ymin = np.float64(ymin) xmax = np.float64(xmax) ymax = np.float64(ymax) if xmax == xmin or ymax == ymin: print(xml_file) # 将Anchor的长宽放入dateset,运行kmeans获得Anchor dataset.append([xmax - xmin, ymax - ymin]) return np.array(dataset) ANNOTATIONS_PATH = "/data/jupiter/project/dataset/209_VOC_new/Annotations" #xml文件所在文件夹 CLUSTERS = 9 #聚类数量,anchor数量 INPUTDIM = 416 #输入网络大小 data = load_dataset(ANNOTATIONS_PATH) out = kmeans(data, k=CLUSTERS) print('Boxes:') out_handle = np.array(out)*INPUTDIM print(out_handle.astype(np.int32)) print("Accuracy: {:.2f}%".format(avg_iou(data, out) * 100)) final_anchors = np.around(out[:, 0] / out[:, 1], decimals=2).tolist() print("Before Sort Ratios:\n {}".format(final_anchors)) print("After Sort Ratios:\n {}".format(sorted(final_anchors)))Boxes: [[ 8 34] [234 256] [279 239] [ 52 63] [ 6 28] [ 5 26] [ 24 33] [ 10 37] [177 216]] Accuracy: 82.93% Before Sort Ratios: [0.24, 0.92, 1.17, 0.83, 0.23, 0.19, 0.74, 0.28, 0.82] After Sort Ratios: [0.19, 0.23, 0.24, 0.28, 0.74, 0.82, 0.83, 0.92, 1.17]参考资料YOLOv3使用自己数据集——Kmeans聚类计算anchor boxes目标检测算法之YOLO系列算法的Anchor聚类
VOC数据集的Anchor聚类--Kmeans算法实现 1.K-means算法具体介绍参考:Kmeans算法简介k-means聚类的算法运行过程:(1)选择k个初始聚类中心 (2)计算每个对象与这k个中心各自的距离,按照最小距离原则分配到最邻近聚类 (3)使用每个聚类中的样本均值作为新的聚类中心 (4)重复步骤(2)和(3)直到聚类中心不再变化 (5)结束,得到k个聚类2.算法实现2.1数据加载函数封装# STEP1:加载数据集,获取所有box的width、height import os from progressbar import * import xmltodict import numpy as np def load_dataset(data_root): xml_dir= os.path.join(data_root,"Annotations") #xml文件路径(Annotations) width_height_list = [] #用于存储统计结果 #进度条功能 widgets = ['box width_height 统计: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=len(os.listdir(xml_dir))).start() count = 0 for xml_file in os.listdir(xml_dir): # 拼接xml文件的path xml_file_path = os.path.join(xml_dir,xml_file) # 读取xml文件到字符串 with open(xml_file_path) as f: xml_str = f.read() # xml字符串转为字典 xml_dic = xmltodict.parse(xml_str) # 获取图片的width、height img_width = float(xml_dic["annotation"]["size"]["width"]) img_height = float(xml_dic["annotation"]["size"]["height"]) # 获取xml文件中的所有objects obj_list = [] objects = xml_dic["annotation"]["object"] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: obj_list.append(obj) else: # xml文件中包含1个object obj_list.append(objects) #print(obj_list) # width_height布统计 for obj in obj_list: #box 的height\width归一化 box_width = (float(obj['bndbox']["xmax"]) - float(obj['bndbox']["xmin"]))/img_width box_height = (float(obj['bndbox']["ymax"]) - float(obj['bndbox']["ymin"]))/img_height width_height_list.append([box_width,box_height]) #更新进度条 count += 1 pbar.update(count) #释放进度条 pbar.finish()调用效果#输出统计结果信息 data_root = "/data/jupiter/project/dataset/209_VOC_new" width_height_list = load_dataset(data_root) width_height_np = np.array(width_height_list) print("clustering feature data is ready. shape = (N object, width and height) = {}".format(width_height_np.shape))box width_height 统计: 100% |###############| Elapsed Time: 0:00:35 Time: 0:00:35 clustering feature data is ready. shape = (N object, width and height) = (10670, 2)2.2 将未聚类前的统计结果绘图表示# 将未聚类前的统计结果绘图表示 import matplotlib.pyplot as plt plt.figure(figsize=(10,10)) plt.scatter(width_height_np[:,0],width_height_np[:,1],alpha=0.3) plt.title("Clusters",fontsize=20) plt.xlabel("normalized width",fontsize=20) plt.ylabel("normalized height",fontsize=20) plt.show()调用效果2.3 实现距离评估函数(这里用的是iou)这里iou的计算公式为:$$ \begin{array}{rl} IoU &= \frac{\textrm{intersection} }{ \textrm{union} - \textrm{intersection} }\\ \textrm{intersection} &= Min(w_1,w_2) Min(h_1,h_2)\\ \textrm{union} & = w_1 h_1 + w_2 h_2 \end{array} $$图示代码实现import numpy as np # 数据间距离评估函数 def iou(box, clusters): """ 计算一个ground truth边界盒和k个先验框(Anchor)的交并比(IOU)值。 参数box: 元组或者数据,代表ground truth的长宽。 参数clusters: 形如(k,2)的numpy数组,其中k是聚类Anchor框的个数 返回:ground truth和每个Anchor框的交并比。 """ x = np.minimum(clusters[:, 0], box[0]) y = np.minimum(clusters[:, 1], box[1]) if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0: raise ValueError("Box has no area") intersection = x * y box_area = box[0] * box[1] cluster_area = clusters[:, 0] * clusters[:, 1] iou_ = intersection / (box_area + cluster_area - intersection) return iou_2.4实现kmeans聚类函数# 实现kmeans聚类函数 def kmeans(boxes, k): """ 利用IOU值进行K-means聚类 参数boxes: 形状为(r, 2)的ground truth框,其中r是ground truth的个数 参数k: Anchor的个数 返回值:形状为(k, 2)的k个Anchor框 """ # 即是上面提到的r rows = boxes.shape[0] # 距离数组,计算每个ground truth和k个Anchor的距离 distances = np.empty((rows, k)) # 上一次每个ground truth"距离"最近的Anchor索引 last_clusters = np.zeros((rows,)) # 设置随机数种子 np.random.seed() # 初始化聚类中心,k个簇,从r个ground truth随机选k个 clusters = boxes[np.random.choice(rows, k, replace=False)] # 开始聚类 while True: # 计算每个ground truth和k个Anchor的距离,用1-IOU(box,anchor)来计算 for row in range(rows): distances[row] = 1 - iou(boxes[row], clusters) # 对每个ground truth,选取距离最小的那个Anchor,并存下索引 nearest_clusters = np.argmin(distances, axis=1) # 如果当前每个ground truth"距离"最近的Anchor索引和上一次一样,聚类结束 if (last_clusters == nearest_clusters).all(): break # 更新簇中心为簇里面所有的ground truth框的均值 for cluster in range(k): clusters[cluster] = np.median(boxes[nearest_clusters == cluster], axis=0) # 更新每个ground truth"距离"最近的Anchor索引 last_clusters = nearest_clusters return clusters,nearest_clusters2.4 调用测试CLUSTERS = 9 #聚类数量,anchor数量 INPUTDIM = 416 #输入网络大小 clusters_center_list,nearest_clusters = kmeans(width_height_np, k=CLUSTERS) clusters_center_list_handle = np.array(clusters_center_list)*INPUTDIM # 得到最终填入YOLOv3 的cfg文件中的anchor print('Boxes:') print(clusters_center_list_handle.astype(np.int32)) Boxes: [[ 9 37] [235 239] [ 4 30] [ 24 33] [ 5 21] [ 52 63] [ 5 26] [ 7 28] [ 6 33]]2.5聚类结果绘制与效果评估(mean_iou)查看数据聚类结果import seaborn as sns current_palette = list(sns.xkcd_rgb.values()) def plot_cluster_result(plt,clusters,nearest_clusters,mean_iou,width_height_np,k): for icluster in np.unique(nearest_clusters): pick = nearest_clusters==icluster c = current_palette[icluster] plt.rc('font', size=8) plt.plot(width_height_np[pick,0],width_height_np[pick,1],"p", color=c, alpha=0.5,label="cluster = {}, N = {:6.0f}".format(icluster,np.sum(pick))) plt.text(clusters[icluster,0], clusters[icluster,1], "c{}".format(icluster), fontsize=20,color="red") plt.title("Clusters=%d" %k) plt.xlabel("width") plt.ylabel("height") plt.legend(title="Mean IoU = {:5.4f}".format(mean_iou)) # achor结果评估 def avg_iou(boxes, clusters): """ 计算一个ground truth和k个Anchor的交并比的均值。 """ return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])]) figsize = (7,5) plt.figure(figsize=figsize) mean_iou = avg_iou(width_height_np, out) plot_cluster_result(plt,clusters_center_list,nearest_clusters,mean_iou,width_height_np,k=CLUSTERS)运行效果查看聚类中心分布w = width_height_np[:, 0].tolist() h = width_height_np[:, 1].tolist() centroid_w=clusters_center_list[:,0].tolist() centroid_h=clusters_center_list[:,1].tolist() plt.figure(dpi=200) plt.title("kmeans") plt.scatter(w, h, s=10, color='b') plt.scatter(centroid_w,centroid_h,s=10,color='r') plt.show()运行效果3.汇总简略版#coding=utf-8 import xml.etree.ElementTree as ET import numpy as np import glob def iou(box, clusters): """ 计算一个ground truth边界盒和k个先验框(Anchor)的交并比(IOU)值。 参数box: 元组或者数据,代表ground truth的长宽。 参数clusters: 形如(k,2)的numpy数组,其中k是聚类Anchor框的个数 返回:ground truth和每个Anchor框的交并比。 """ x = np.minimum(clusters[:, 0], box[0]) y = np.minimum(clusters[:, 1], box[1]) if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0: raise ValueError("Box has no area") intersection = x * y box_area = box[0] * box[1] cluster_area = clusters[:, 0] * clusters[:, 1] iou_ = intersection / (box_area + cluster_area - intersection) return iou_ def avg_iou(boxes, clusters): """ 计算一个ground truth和k个Anchor的交并比的均值。 """ return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])]) def kmeans(boxes, k): """ 利用IOU值进行K-means聚类 参数boxes: 形状为(r, 2)的ground truth框,其中r是ground truth的个数 参数k: Anchor的个数 参数dist: 距离函数 返回值:形状为(k, 2)的k个Anchor框 """ # 即是上面提到的r rows = boxes.shape[0] # 距离数组,计算每个ground truth和k个Anchor的距离 distances = np.empty((rows, k)) # 上一次每个ground truth"距离"最近的Anchor索引 last_clusters = np.zeros((rows,)) # 设置随机数种子 np.random.seed() # 初始化聚类中心,k个簇,从r个ground truth随机选k个 clusters = boxes[np.random.choice(rows, k, replace=False)] # 开始聚类 while True: # 计算每个ground truth和k个Anchor的距离,用1-IOU(box,anchor)来计算 for row in range(rows): distances[row] = 1 - iou(boxes[row], clusters) # 对每个ground truth,选取距离最小的那个Anchor,并存下索引 nearest_clusters = np.argmin(distances, axis=1) # 如果当前每个ground truth"距离"最近的Anchor索引和上一次一样,聚类结束 if (last_clusters == nearest_clusters).all(): break # 更新簇中心为簇里面所有的ground truth框的均值 for cluster in range(k): clusters[cluster] = np.median(boxes[nearest_clusters == cluster], axis=0) # 更新每个ground truth"距离"最近的Anchor索引 last_clusters = nearest_clusters return clusters # 加载自己的数据集,只需要所有labelimg标注出来的xml文件即可 def load_dataset(path): dataset = [] for xml_file in glob.glob("{}/*xml".format(path)): tree = ET.parse(xml_file) # 图片高度 height = int(tree.findtext("./size/height")) # 图片宽度 width = int(tree.findtext("./size/width")) for obj in tree.iter("object"): # 偏移量 xmin = int(obj.findtext("bndbox/xmin")) / width ymin = int(obj.findtext("bndbox/ymin")) / height xmax = int(obj.findtext("bndbox/xmax")) / width ymax = int(obj.findtext("bndbox/ymax")) / height xmin = np.float64(xmin) ymin = np.float64(ymin) xmax = np.float64(xmax) ymax = np.float64(ymax) if xmax == xmin or ymax == ymin: print(xml_file) # 将Anchor的长宽放入dateset,运行kmeans获得Anchor dataset.append([xmax - xmin, ymax - ymin]) return np.array(dataset) ANNOTATIONS_PATH = "/data/jupiter/project/dataset/209_VOC_new/Annotations" #xml文件所在文件夹 CLUSTERS = 9 #聚类数量,anchor数量 INPUTDIM = 416 #输入网络大小 data = load_dataset(ANNOTATIONS_PATH) out = kmeans(data, k=CLUSTERS) print('Boxes:') out_handle = np.array(out)*INPUTDIM print(out_handle.astype(np.int32)) print("Accuracy: {:.2f}%".format(avg_iou(data, out) * 100)) final_anchors = np.around(out[:, 0] / out[:, 1], decimals=2).tolist() print("Before Sort Ratios:\n {}".format(final_anchors)) print("After Sort Ratios:\n {}".format(sorted(final_anchors)))Boxes: [[ 8 34] [234 256] [279 239] [ 52 63] [ 6 28] [ 5 26] [ 24 33] [ 10 37] [177 216]] Accuracy: 82.93% Before Sort Ratios: [0.24, 0.92, 1.17, 0.83, 0.23, 0.19, 0.74, 0.28, 0.82] After Sort Ratios: [0.19, 0.23, 0.24, 0.28, 0.74, 0.82, 0.83, 0.92, 1.17]参考资料YOLOv3使用自己数据集——Kmeans聚类计算anchor boxes目标检测算法之YOLO系列算法的Anchor聚类 -
ShuffleNet-v2简介与实现 1.原论文ECCV2018--ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design2.设计理念目前衡量模型复杂度的一个通用指标是FLOPs,具体指的是multiply-add数量,但是这却是一个间接指标,因为它不完全等同于速度。如图1中的(c)和(d)可以看到相同FLOPs的两个模型,其速度却存在差异。这种不一致主要归结为两个原因,首先影响速度的不仅仅是FLOPs,如内存使用量(memory access cost, MAC),这不能忽略,对于GPUs来说可能会是瓶颈。另外模型的并行程度也影响速度,并行度高的模型速度相对更快。另外一个原因,模型在不同平台上的运行速度是有差异的,如GPU和ARM,而且采用不同的库也会有影响。3.根据设计理念及实验得出的4条基本设计准则3.1探索实验据此,作者在特定的平台下研究ShuffleNetv1和MobileNetv2的运行时间,并结合理论与实验得到了4条实用的指导原则:G1:同等通道大小最小化内存访问量对于轻量级CNN网络,常采用深度可分割卷积(depthwise separable convolutions),其中点卷积( pointwise convolution)即1x1卷积复杂度最大。这里假定输入和输出特征的通道数分别为 $c1$和$c2$,特征图的空间大小为$h \times w$,那么1x1卷积的FLOPs为$$ B=hwc_1c_2 $$对应的MAC(memory access cost)为$$ MAC = hw(c_1+c_2)+c_1c_2 $$根据均值不等式(这里假定内存足够),固定B时,MAC存在下限(令$c_2=\frac{B}{hwc_1}$),则$$ MAC \ge 2 \sqrt{hwB} + \frac{B}{hw} $$仅当$c_1=c_2$时,MAC取最小值,这个理论分析也通过实验得到证实,如下表所示,通道比为1:1时速度更快。G2:过量使用组卷积会增加MAC(memory access cost)组卷积(group convolution)是常用的设计组件,因为它可以减少复杂度却不损失模型容量。但是这里发现,分组过多会增加MAC(memory access cost)。对于组卷积,FLOPs为(其中g为组数):$$ B = hwc_1c_2/g $$对应的MAC(memory access cost)为$$ MAC = hwc_1+Bg/c_1+B/hw $$可以看到,在输入确定,B相同时,当g增加时,MAC(memory access cost)会同时增加,下表是对应的实验,所以明智之举是不要使用太大 ![[公式]](https://www.zhihu.com/equation?tex=g) 的组卷积。G3:网络碎片化会降低并行度一些网络如Inception,以及Auto ML自动产生的网络NASNET-A,它们倾向于采用“多路”结构,即存在一个lock中很多不同的小卷积或者pooling,这很容易造成网络碎片化,减低模型的并行度,相应速度会慢,这也可以通过实验得到证明。G4:不能忽略元素级操作(比如ReLU和Add)对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC(memory access cost)。这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。4.ShuffleNet-v1 基本结构及存在的问题4.1ShuffleNet-v1基本结构其中:(a) the basic ShufflleNet unit;(b) the ShufflleNet unit for spatial down sampling (2×);4.2ShuffleNet-v1存在的问题在ShuffleNetv1的模块中,大量使用了1x1组卷积,这违背了G2原则,另外v1采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同,这违背了G1原则。同时使用过多的组,也违背了G3原则。短路连接中存在大量的元素级Add运算,这违背了G4原则。5.ShuffleNet-v2基本块及改进分析5.1ShuffleNet-v2基本块根据前面的4条准则,作者分析了ShuffleNetv1设计的不足,并在此基础上改进得到了ShuffleNetv2,两者模块上的对比如下图所示:其中(c) the basic ShufflleNetv2 unit;(d) the ShufflleNetv2 unit for spatial down sampling (2×);DWConv: depthwise convolutionGConv:group convolution对于ShufflleNetv2基本块(the ShufflleNetv2 unit)还可以选择是否采用SE(Squeeze-and-Excitation)模块和残差(residual)结构5.2ShuffleNetv2的改进分析为了改善v1的缺陷,根据四条原则,作者提出了shufflenet v2。v2版本引入了一种新的运算:channel split(如上图网路结构中的图c)。channel split的做法:在开始时先将输入特征图在通道维度分成两个分支:通道数分别为 $c'$ 和 $c-c'$ ,实际实现时$c'=c/2$ 。一个是identity,一个经过三个conv,然后concat到一起,这个满足G4。右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起。取替了element-wise操作add。最后经过channel shuffle将两个分支的信息进行交流。channel split的作用:第一,划分一半到右分支,意味着右边计算量减少,从而可以提高channel数,提高网络capacity。第二,左分支相当于一种特征重用(feature reuse), 跟DenseNet和CondenseNet一样的思想。下图(a)为DenseNet的从source layer到target layer连接的权重的大小,可见target层前1-3层的信息对当前层帮助较大,而越远的连接比较多余。图(b)为ShuffleNet v2的情况,因为shuffle操作会导致每次会有一半的channel到下一层。因此,作者认为shufflenet跟densenet一样的利用到了feature reuse,所以有效。6.ShuffleNet-v2完整网络结构其中:1个stage=1个DSampling+Repeat个BasicUnit7.ShuffleNet-v2基本块实现(pytorch)7.1Channel Shuffle图示实现步骤假定将输入层分为 g 组,总通道数为 g × n 。首先你将通道那个维度拆分为 (g,n) 两个维度然后将这两个维度转置变成 (n,g)最后重新reshape成一个维度 g × n 。代码# Channel Shuffle def shuffle_chnls(x, groups=2): """Channel Shuffle""" bs, chnls, h, w = x.data.size() # 如果通道数不是分组的整数被,则无法进行Channel Shuffle操作,直接返回x if chnls % groups: return x # 计算用于Channel Shuffle的一个group的的通道数 chnls_per_group = chnls // groups # 执行channel shuffle操作 x = x.view(bs, groups, chnls_per_group, h, w) # 将通道那个维度拆分为 (g,n) 两个维度 x = torch.transpose(x, 1, 2).contiguous() # 将这两个维度转置变成 (n,g) x = x.view(bs, -1, h, w) # 最后重新reshape成一个维度 g × n g\times ng×n return x7.2ShufflleNetv2基本块( the basic ShufflleNetv2 unit)基本结构图示增加SE(Squeeze-and-Excitation)模块和残差(residual)结构后的基本块结构图示代码# 封装一个Conv+BN+RELU的基本块 class BN_Conv2d(nn.Module): def __init__(self, in_channels, out_channels, kernel_size, stride, padding, dilation=1, groups=1, bias=False, activation=True): # dilation=1-->卷积核膨胀 super(BN_Conv2d, self).__init__() layers = [nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias), nn.BatchNorm2d(out_channels)] if activation: layers.append(nn.ReLU(inplace=True)) self.seq = nn.Sequential(*layers) def forward(self, x): return self.seq(x)# ShuffleNet-v2基本块 class BasicUnit(nn.Module): def __init__(self, in_chnls, out_chnls, is_se=False, is_residual=False, c_ratio=0.5, groups=2): super(BasicUnit, self).__init__() self.is_se, self.is_res = is_se, is_residual # 是否使用SE结构和残差结构 self.l_chnls = int(in_chnls * c_ratio) # 左侧输入通道数 self.r_chnls = in_chnls - self.l_chnls # 右侧输入通道数 self.ro_chnls = out_chnls - self.l_chnls # 右侧输出通道数 self.groups = groups # layers self.conv1 = BN_Conv2d(self.r_chnls, self.ro_chnls, 1, 1, 0) self.dwconv2 = BN_Conv2d(self.ro_chnls, self.ro_chnls, 3, 1, 1, # same padding, depthwise conv groups=self.ro_chnls, activation=None) act = False if self.is_res else True self.conv3 = BN_Conv2d(self.ro_chnls, self.ro_chnls, 1, 1, 0, activation=act) # 是否使用SE模块和residual结构 if self.is_se: self.se = SE(self.ro_chnls, 16) if self.is_res: self.shortcut = nn.Sequential() if self.r_chnls != self.ro_chnls: self.shortcut = BN_Conv2d(self.r_chnls, self.ro_chnls, 1, 1, 0, activation=False) def forward(self, x): # channel split 操作 x_l = x[:, :self.l_chnls, :, :] x_r = x[:, self.r_chnls:, :, :] # right path out_r = self.conv1(x_r) out_r = self.dwconv2(out_r) out_r = self.conv3(out_r) # 是否使用SE模块和residual结构 if self.is_se: coefficient = self.se(out_r) out_r *= coefficient if self.is_res: out_r += self.shortcut(x_r) # concatenate out = torch.cat((x_l, out_r), 1) return shuffle_chnls(out, self.groups)7.3ShufflleNetv2下采样基本块(the ShufflleNetv2 unit for spatial down sampling)图示代码# SuffleNet-v2下采样基本块 class DSampling(nn.Module): def __init__(self, in_chnls, groups=2): super(DSampling, self).__init__() self.groups = groups # down-sampling(通过stride=2实现), depth-wise conv(通过groups=in_chnls实现). self.dwconv_l1 = BN_Conv2d(in_chnls, in_chnls, 3, 2, 1, groups=in_chnls, activation=None) self.conv_l2 = BN_Conv2d(in_chnls, in_chnls, 1, 1, 0) self.conv_r1 = BN_Conv2d(in_chnls, in_chnls, 1, 1, 0) self.dwconv_r2 = BN_Conv2d(in_chnls, in_chnls, 3, 2, 1, groups=in_chnls, activation=False) self.conv_r3 = BN_Conv2d(in_chnls, in_chnls, 1, 1, 0) def forward(self, x): # left path out_l = self.dwconv_l1(x) out_l = self.conv_l2(out_l) # right path out_r = self.conv_r1(x) out_r = self.dwconv_r2(out_r) out_r = self.conv_r3(out_r) # concatenate out = torch.cat((out_l, out_r), 1) return shuffle_chnls(out, self.groups)8.ShuffleNet-v2网络结构实现# TODO参考资料ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture DesignShuffleNetV2:轻量级CNN网络中的桂冠轻量级网络之ShuffleNet v2shufflenet中channel shuffle原理PyTorch实现ShuffleNet-v2亲身实践
-
计算机技术核心期刊大全(2020年最新整理) 1、计算机学报简介:《计算机学报》是中国计算机领域的权威学术刊物。 其宗旨是报道我国计算机科学和技术领域最高水平的科研成果。 《计算机学报》创立于1978年,以中文编辑形式与读者见面,同时以英文摘要形式向国际各大检索系统提供基本内容介绍。 本刊是中国计算机领域的代表性学术刊物,作为科学研究档案,代表了计算机领域各研究阶段的水平。收录:北京大学《中文核心期刊总览》EI 工程索引(美)(2018)CSCD 中国科学引文数据库(2017-2018年度)(含扩展版)统计源核心期刊(中国科技论文核心期刊) 2、软件学报简介:《软件学报》 (月刊)创刊于1990年,由中国科学医院软件研究所和中国计算机学会联合主办。 刊载软件各领域原创研究成果的期刊,刊载的论文均经过严格的同行专家评议,2000年获中国科学院优秀科技期刊等奖。《软件学报》主要面向全球华人计算机软件学者,为全球华人计算机科学和致力于与软件技术发展同步创设以中文为中心的《中文国际软件学术杂志》的中国人提供学术交流平台。 刊载反映计算机科学和计算机软件更新理论,重视更新方法和新技术和学科发展趋势的文章主要有理论计算机科学,算法设计和分析,系统软件和软件工程,模式识别和人工数据库技术、计算机网络、信息安全、计算机图形学和计算机设计支持、多媒体技术和其他相关内容。3、自动化学报简介:《自动化学报》 (月刊)创刊于1963年,是中国自动化学会、中国科学院自动化研究所共同主办的高级学术期刊。 刊载自动化科学和技术领域的高水平理论性和应用性的科研成果。 内容如下:1)自动控制2 )系统理论和系统工程3 )自动化工过程技术和应用4 )自动化系统计算机辅助技术5 )机器人6 )人工智能和智能控制7 )模式识别和图像处理8 )信息处理和信息服务9 )基于网络的自动化等。4、计算机研究与发展简介:《计算机研究与发展》 (月刊)创刊于1958年,中国科学医院计算技术研究所,中国计算机学会主办。 刊载内容: 计算机科学技术领域高水平的学术论文,最新科研成果和重大应用成果。 刊载内容:评估、计算机基础理论、软件技术、信息安全、计算机网络、图形图像、体系结构、人工智能、计算机应用、数据库技术、存储技术和计算机相关领域。5、控制与决策简介:《控制与决策》创刊于1986年,由教育部主管、东北大学主办。本刊是自动控制与管理决策领域的学术性期刊,主要刊登自动控制理论及其应用,系统理论与系统工程,决策理论与决策方法,自动化技术及其应用,人工智能与智能控制,机器人,以及自动控制与决策领域的其他重要课题。主要栏目有:综述与评论、论文与报告、短文、信息与动态等。6、中国图象图形学报简介:《中国图象图形学报》是由中国科学院遥感与数字地球研究所、中国图象图形学会、北京应用物理与计算数学研究所共同创办,是集计算机图像图形高科技理论、技术方法与应用研究成果产业化于一体的综合性学术期刊。主要刊登图像图形科学及其密切相关领域的基础研究和应用研究方面,并具有创新性的、高水平科研学术论文,论文形式主要有综述、技术报告,项目进展、学术动态、新技术评论、新产品介绍和产业化研究等。内容涉及图像分析和识别、图像理解和计算机视觉、计算机图形学、虚拟现实和增强现实、系统仿真、动漫等众多领域,同时还根据各时期的研究热点和前沿课题开设相应的主 题专栏。读者对象不从事国防、军事、航空、航天、通信、电子、汽车、农业、气象、环保、遥感、测绘、油田、建筑、交通、金融、电信、教育、医疗、影视、艺术等科技人员、企业主管及高等院校的研究生,大学生。7、计算机辅助设计与图形学学报简介:创刊于1989年,是我国CAD和计算机图形学领域第一个公开出版的学术刊物,原为季刊,1996年起改为双月刊,从2000年起改为月刊。该刊以快速传播CAD与计算机图形学领域的知识与经验为目的,刊登有创新的学术论文,报导最新科研成果和学术动态,及时反映该领域发展水平与发展方向。读者对象为从事CAD和计算机图形及其他有关学科的科研、工程技术人员及高等院校师生。8、计算机应用研究简介:《计算机应用研究》创刊于1984年,是由国家科技部所属四川省计算机研究院主办,北京、天津、山东、吉林、云南、贵州、安徽、河南、广西、甘肃、内蒙古等十余省市计算中心协办的计算技术类学术刊物。主要刊载内容包括本学科领域高水平的学术论文、本学科最新科研成果和重大应用成果。栏目内容涉及计算机学科新理论、计算机基础理论、算法理论研究、算法设计与分析、系统软件与软件工程技术、模式识别与人工智能、体系结构、先进计算、并行处理、数据库技术、计算机网络与通信技术、信息安全技术、计算机图像图形学及其最新热点应用技术。9、计算机科学简介:《计算机科学》(Computer Science)创刊于1974年1月(月刊),由重庆西南信息有限公司(原科技部西南信息中心)主管主办,曾用刊名计算机应用与应用数学,是中国计算机学会(CCF)会刊。主要报道国内外计算机科学与技术的发展动态、涉及面广的方法论与技术、反映新苗头且能起承先启后作用的研究成果。10、计算机应用简介:《计算机应用》创刊于1981年,是中国计算机学会会刊。本刊旨在介绍计算机应用技术,推动经济发展和科技进步,促进计算机应用创新的开发。 多年来,中国计算机学会一直关注着国内计算机各应用领域的专家。读者对象:计算机应用工程技术人员、大专院校师生、企事业单位管理干部、科研院所从事计算机开发应用人员、计算机公司职员等必备的工具,是启迪思维、开拓进取、更新知识、开发应用的良师益友。11、计算机工程简介:《计算机工程》创刊于1975年,是中国电子科技集团公司第三十二研究所(华东计算技术研究所)和上海市计算机学会主办的学术性刊物,刊登内容: 热点与综述、人工智能与模式识别、先进计算与数据处理、网络空间安全、移动互联与通信技术、体系结构与软件技术、图形图像处理、开发研究与工程应用等。12、控制理论与应用简介:《控制理论与应用》1984年创刊,是教育部主管、由华南理工大学和中科院数学与系统科学研究院联合主办的全国学术刊物。主要报道在控制理论与应用方面的高水平学术论文,特别是系统控制、最优化和自动化领域中的新兴问题、原创方法及尖端技术,为控制领域的科学家和工程师们提供一个交流最新成果的平台。主要报道系统控制科学中具有新观念、新思想的理论研究成果及其在各个领域中, 特别是高科技领域中的应用研究成果和在国民经济有关领域技术开发、技术改造中的应用成果. 内容包括: 1) 系统建模、辨识与估计; 2) 数据驱动建模与控制;3)过程控制; 4)智能控制; 5)网络控制; 6) 非线性系统控制; 7) 随机系统控制; 8) 预测控制; 9) 多智能体系统及分布式控制; 10)鲁棒与自适应控制;11) 系统优化理论与算法; 12) 混杂系统与离散事件系统; 13)工程控制系统;14)航空与航天控制系统;15)新兴战略产业中的控制系统;16)博弈论与社会网络;17)微纳与量子系统;18)模式识别与机器学习;19)智能机器人;20) 先进控制理论在实际系统中的应用; 21)系统控制科学中的其它重要问题。《控制理论与应用》的读者对象是从事控制理论与应用研究的科技人员、高校师生及其他有关人员。设置的栏目主要有: 综述与评论,长论文,论文, 短文, 书刊评介, 读者来信, 国内外学术活动信息等。13、机器人简介:《机器人》是经中华人民共和国新闻出版局批准,由中国科学院主管、中国科学院沈阳自动化研究所、中国自动化学会联合主办类核心期刊,主要报告中国在机器人学和相关领域创新、高水平、重要学术进展和研究成果,由中国科学出版社出版。本刊读者包括国内外大学、科研机构和相关技术领域的教师、研究者、工程技术人员和博士、硕士研究生等。14、中文信息学报简介:《中文信息学报》 (双月刊)创刊于1986年,经国家科学委员会批准,由中国科学技术协会主管、中文信息学会和中国科学院软件研究所共同出版,是中文信息学会会刊。着重刊载中文信息处理的基础理论和应用技术研究的学术论文,以及相关综述、研究成果、技术报告、出版物评论、专题讨论、国内外学术动态等。 读者对象:广泛的计算机科学研究者、工程技术人员、软件开发与应用者、高校师生、研究生等,是计算机界中文信息处理者的重要参考书。15、模式识别与人工智能简介:《模式识别与人工智能》 (双月刊)创刊于1989年,是中国自动化学会、国家智能计算机研发中心和中国科学院合肥智能机械研究所共同主办、科学出版社出版的学术期刊。 本刊主要发表模式识别、人工智能、智能系统等研究成果和进展,旨在推动信息科学技术的发展。16、计算机集成制造系统简介:《计算机集成制造系统》 (月刊)创刊于1995年,国家863计划CIMS主题办公室,中国兵器工业第210研究所主办。 为国家级学术刊物交流国内外CIMS的研究、开发和应用信息,旨在推动和促进中国CIMS的发展。 主要报道国内外关系发展计算机集成制造系统的政策措施、重点、趋势、科研动态、科技成果、推广应用、产品开发和学术活动等内容。 有综述、论文、专家论坛、企业实践和动态信息等栏目。17、计算机工程与应用简介:《计算机工程与应用》是由中国电子科技集团公司主管,华北计算技术研究所主办的面向计算机全行业的综合性学术刊物,报导范围为行业最新研究成果与学术领域最新发展动态;具有先进性和推广价值的工程方案;有独立和创新见解的学术报告;先进、广泛、实用的开发成果。读者对象为计算机相关专业科研人员,工程项目的决策、开发、设计及应用人员,大专院校师生。18、系统仿真学报简介:《系统仿真学报》创刊于1989年7月,是中国仿真学会会刊(2016年2月,原中国系统仿真学会变更为中国仿真学会),由中国仿真学会和北京仿真中心联合主办,是中国仿真技术领域具有权威性、代表性的学术刊物。其宗旨是报道我国仿真技术领域具有国际、国内领先水平的科研成果,刊登具有创新性学术见解的研究论文。19、传感技术学报简介:《传感技术学报》创刊于1988年,由中华人民共和国教育部主管,是中国微米纳米技术学会会刊,挂靠东南大学编辑、出版和发行的学术性刊物。覆盖技术领域:MEMS、各类传感器材料、结构、器件和系统、传感器信号处理、无线传感技术、传感器应用。20、小型微型计算机系统简介:《小型微型计算机系统》创刊于1980年。该刊由中国科学院主管,中国科学院沈阳计算技术研究所主办,为中国计算机学会会刊,月刊,国内外公开发行。刊登的内容涵盖了计算机学科的各个领域,包括计算机科学理论、体系结构、软件、数据库理论、网络(含传感器网络)、人工智能与算法、服务计算、计算机图形与图像等。21、计算机工程与设计简介:《计算机工程与设计》创办于1980年,是由中国航天科工集团主管、中国航天科工集团七〇六所主办的中国计算机技术领域的学术性期刊。 办刊宗旨:本刊以传播新技术、促进学术交流为宗旨,坚持深度与广度、理论与应用相结合的方针,着力报道计算机前沿技术和热点技术,欢迎有创新和独立学术见解的学术论文,包括基金项目论文、获奖课题论文、学术会议优秀论文、博士和硕士论文等。22、遥感技术与应用简介:《遥感技术与应用》是综合性学术刊物,主要刊登国内外遥感理论、技术及应用研究领域的学术论文与综述,优先报道国内外遥感研究与应用的新技术、新理论、新方法和新成果,推动高新技术在地球科学研究及社会发展中的应用,重点介绍国家自然科学基金项目、交流国家攀登计划、攻关计划工作等科研成果。针对目前遥感领域的热点问题和发展动态,经第六届编委会讨论决定,将栏目细化调整为微波遥感、光学遥感、数据处理、模型与反演、遥感应用、专家述评、GIS、深空探测、重大项目、综述等。23、国土资源遥感简介:《国土资源遥感》是由中国地质调查局主管,中国自然资源航空物探遥感中心主办的技术性刊物(季刊,国内外公开发行),创刊于1989年。主要刊登实用性强的遥感、GIS及GPS(3S)技术理论及其应用论文,宣传3S技术在国土资源调查与开发、国土整治的规划与管理,环境和灾害监测,水文地质、工程地质勘查,建设工程选址、选线及城市规划等领域应用的新方法和重要成果,以从事国土资源遥感及其相关研究领域的研究人员、应用人员及大专院校有关师生为读者对象。24、计算机科学与探索简介:《计算机科学与探索》是由中国电子科技集团公司主管、华北计算技术研究所主办的国内外公开发行的高级学术期刊。报道计算机(硬件、软件)各学科具有创新性、前沿性、开拓性、探索性的科研成果。 内容包括高性能计算机、体系结构、并行处理、计算机科学更新理论、算法设计与分析、人工智能和模式识别、系统软件、软件工程、数据库、计算机网络、信息安全包括图形学和计算机辅助设计、虚拟现实、多媒体技术和交叉学科的相互渗透和新理论的推导等。25、信息与控制简介:《信息与控制》是经中华人民共和国新闻出版总署批准,由中国科学院主管,中国科学院沈阳自动化研究所、中国自动化学会共同主办的科技类核心期刊,主要刊载信息与控制科学领域基础研究和应用基础研究方面具有创新性的、高水平的、有重要意义的研究成果,由科学出版社出版。重点关注控制科学与技术、与控制理论相关的应用信息技术在机械制造、能源电力、冶金化工、资源环境、航空工业以及国防工业等国家重要高科技和经济领域中的应用研究成果。主要内容包括:1)控制理论与控制工程;2)智能信息处理;3)人工智能与模式识别;4)先进控制与优化技术;5)企业信息管理与信息系统;6)工业控制网络与系统;7)人机系统等。26、智能系统学报简介:《智能系统学报》是由中国人工智能学会和哈尔滨工程大学联合主办,是中国人工智能学会会刊。主要刊登神经网络与神经计算、智能信息处理、自然语言理解、智能系统工程、机器翻译、复杂系统、机器学习、知识工程与分布式智能、机器人、智能制造、粗糙集与软计算、免疫系统、机器感知与虚拟现实、智能控制与智能管理、可拓工程、人工智能基础等内容。27、计算机应用与软件简介:《计算机应用与软件》创刊于1984年,由上海市计算技术研究所和上海计算机软件技术开发中心共同主办。注重刊登反映计算机应用和软件技术开发应用方面的新理论、新方法、新技术以及创新应用的文章。主要栏目包括:最新技术动态、综合评述、软件技术与研究、数据工程、应用技术与研究、网络与通信、多媒体技术应用、人工智能与识别、图像处理与应用、嵌入式软件与应用、算法、安全技术、信息技术交流及其他相关内容。主要面向从事计算机应用和软件技术开发的科研人员、工程技术人员、高校师生等。28、计算机工程与科学简介:《计算机工程与科学》隶属于中国人民解放军国防科技大学计算机学院,是计算机类综合性学术刊物,1973年创刊,是中国计算机学会会刊,由国防科技大学计算机学院主办。注重刊登计算机学科在理论、工程与应用等方面的研究论文、技术报告和科研成果,主要涉及计算机体系结构、并行处理、超级计算、人工智能、软件工程、计算机仿真、多媒体与可视化、数据库、计算机网络与分布式处理、计算机安全与保密、中文信息处理、微机开发与应用及其他相关内容。29、遥感信息简介:《遥感信息》(双月刊)创刊于1986年,是我国最早批创办的遥感类期刊之一。该刊由中华人民共和国自然资源部主管,中国测绘科学研究院主办。研究内容包括遥感、地理信息系统技术更新理论、传播遥感和地理信息系统技术知识科学,介绍国内外传播新方法遥感和地理信息系统成果的发展趋势。30、控制工程简介:《控制工程》是教育部科技司主管、东北大学主办的学术类期刊。常设栏目: 工业过程管理与决策系统、决策与控制一体化系统、工业过程及控制系统、运动体控制系统、安全监控系统、建模与仿真系统、工业互联网系统、人工智能驱动的自动化等。主要读者对象为从事于自动化工程技术的高等院校教师、研究生,科研院所的研究人员,工矿企业的工程技术人员等。31、微电子学与计算机简介:本刊创于1972年,是中国微电子技术与计算机技术结合的唯一专业的国家汉语核心期刊,同时也是中国计算机学会杂志。 本杂志旨在以认真、追求创新的人为本,研究使用的弘扬科学追求真理。 本刊在国内公开发行,为科研院所、厂矿技术人员、大学教师和学生管理人员及时提供国内微电子和计算机行业的最新科研成果、学术和工程技术动态,是比较实用的参考资料和科学决策的正确依据。32、计算机仿真简介:本刊是我国航天科学工业集团公司的主管,航天科学工业集团十七所主办。 这是模拟技术领域的综合性科技期刊。内容包括国内、外部仿真技术各领域研究理论和技术新成果。 在发行的文章中,近年来国家资金项目约占20%~30%。参考资料计算机技术核心期刊大全(2020年最新整理)计算机核心期刊排名及投稿经验
-
VOC数据集中的图片宽度和高度取整 1.针对问题在数据标注时由于设置问题导致生成的最终的XML文件中的图片的width和height变成了小数,导致在运行某些代码时候会发生异常。样例文件如下所示<?xml version="1.0" ?> <annotation> <folder>/pool/label/209-20180708-08310907/JPEGImages</folder> <filename>/pool/label/209-20180708-08310907/JPEGImages/209-20180708-08310907_frame00731.jpg</filename> <source> <database>Unknown</database> </source> <size> <width>1920.0</width> # 问题所在 <height>1080.0</height> # 问题所在 <depth>3</depth> </size> <segmented>0</segmented> <object> <name>RefuelVehicle</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>664</xmin> <ymin>368</ymin> <xmax>794</xmax> <ymax>464</ymax> </bndbox> </object> ······ </annotation>2.代码实现# 导包 import xmltodict import os from progressbar import * import numpy as np import time import matplotlib.pyplot as plt import xmltodict from xml.dom import minidom data_root = "/data/jupiter/project/dataset/VOC_zd" xml_dir= os.path.join(data_root,"Annotations") #xml文件路径(Annotations) width_height_list = [] #用于存储统计结果 #进度条功能 widgets = ['box width_height 校准: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=len(os.listdir(xml_dir))).start() count = 0 for xml_file in os.listdir(xml_dir): # 拼接xml文件的path xml_file_path = os.path.join(xml_dir,xml_file) # 读取xml文件到字符串 with open(xml_file_path) as f: xml_str = f.read() # xml字符串转为字典 xml_dic = xmltodict.parse(xml_str) # 获取图片的width、height img_width = xml_dic["annotation"]["size"]["width"] img_height = xml_dic["annotation"]["size"]["height"] if img_width.endswith(".0"): xml_dic["annotation"]["size"]["width"] = img_width[:-2] xml_dic["annotation"]["size"]["height"] = img_height[:-2] xmlstr = xmltodict.unparse(xml_dic) xml = minidom.parseString(xmlstr) xml_pretty_str = xml.toprettyxml() with open(xml_file_path,"w") as f: f.write(xml_pretty_str) # 更新进度条 count += 1 pbar.update(count) #释放进度条 pbar.finish()
-
快速使用Mobilenet SSD进行训练VOC格式的数据集 1.训练步骤STEP1:下载代码并配置环境下载代码git clone https://github.com/lufficc/SSD.git cd SSD修改requirements.txttorch==1.5 torchvision==0.5 yacs tqdm opencv-python vizer根据requirements.txt完成环境配置# Required packages: torch torchvision yacs tqdm opencv-python vizer conda create -n ssd-lufficc python=3.8 pip install -r requirements.txt额外补充安装pip install tensorboardX pip install sixSTEP2:在当前目录下建立数据集文件夹的软连接或者复制数据集到当前文件夹完成后文件夹结构├──VOC_data/VOC2007/ ├── Annotations #可以采用软连接的方式避免对大量数据进行复制 ├──放置xml文件 #TODO ├── JPEGImages ├──放置img文件 #TODO ├──ImageSets/Main #可以采用软连接的方式避免对大量数据进行复制 ├── split.py #数据分割脚本,用于生成训练索引文件split.py文件内容import os import random random.seed(0) xmlfilepath=r'./Annotations' saveBasePath=r"./ImageSets/Main/" trainval_percent=0.9 # 可以自己设置 train_percent=0.9 # 可以自己设置 temp_xml = os.listdir(xmlfilepath) total_xml = [] for xml in temp_xml: if xml.endswith(".xml"): total_xml.append(xml) num=len(total_xml) list=range(num) tv=int(num*trainval_percent) tr=int(tv*train_percent) trainval= random.sample(list,tv) train=random.sample(trainval,tr) print("train and val size",tv) print("traub suze",tr) ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w') ftest = open(os.path.join(saveBasePath,'test.txt'), 'w') ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w') fval = open(os.path.join(saveBasePath,'val.txt'), 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest .close()python split.py配置文件根目录的环境变量export VOC_ROOT="./VOC_data" #/path/to/voc_rootSTEP3:修改配置文件 vim configs/mobilenet_v2_ssd320_voc0712.yamlMODEL: NUM_CLASSES: 11 # 修改NUM_CLASSES BOX_HEAD: PREDICTOR: 'SSDLiteBoxPredictor' BACKBONE: NAME: 'mobilenet_v2' OUT_CHANNELS: (96, 1280, 512, 256, 256, 64) PRIORS: FEATURE_MAPS: [20, 10, 5, 3, 2, 1] STRIDES: [16, 32, 64, 107, 160, 320] MIN_SIZES: [60, 105, 150, 195, 240, 285] MAX_SIZES: [105, 150, 195, 240, 285, 330] ASPECT_RATIOS: [[2, 3], [2, 3], [2, 3], [2, 3], [2, 3], [m2, 3]] BOXES_PER_LOCATION: [6, 6, 6, 6, 6, 6] INPUT: IMAGE_SIZE: 320 DATASETS: TRAIN: ("voc_2007_trainval", "voc_2012_trainval") # TODO TEST: ("voc_2007_test", ) SOLVER: MAX_ITER: 120000 LR_STEPS: [80000, 100000] GAMMA: 0.1 BATCH_SIZE: 32 LR: 1e-3 OUTPUT_DIR: 'outputs/mobilenet_v2_ssd320_voc0712STEP4:修改类别信息vim ssd/data/datasets/voc.pyclass VOCDataset(torch.utils.data.Dataset): class_names = ('person','bridgevehicle','luggagevehicle','plane','refuelvehicle','foodvehicle','rubbishvehicle','watervehicle','platformvehicle','tractorvehicle','bridgeconnector') # 改成自己的class注意,类名必须小写 ······STEP5: 模型训练修改默认所用的device和batch_size vim ssd/config/defaults.py# 修改以下内容 _C.MODEL.DEVICE = "cuda:1" # cpu/cuda/cuda:1 _C.SOLVER.BATCH_SIZE = 128 _C.TEST.BATCH_SIZE = 32单GPU# for example, train SSD300: python train.py --config-file configs/mobilenet_v2_ssd320_voc0712.yaml多GPU# for example, train SSD300 with 2 GPUs: export NGPUS=2 python -m torch.distributed.launch --nproc_per_node=$NGPUS train.py --config-file configs/mobilenet_v2_ssd320_voc0712.yaml SOLVER.WARMUP_FACTOR 0.03333 SOLVER.WARMUP_ITERS 10002.模型评估单GPU# for example, evaluate SSD300: python test.py --config-file configs/mobilenet_v2_ssd320_voc0712.yaml多GPU# for example, evaluate SSD300 with 2 GPUs: export NGPUS=2 python -m torch.distributed.launch --nproc_per_node=$NGPUS test.py --config-file configs/mobilenet_v2_ssd320_voc0712.yaml3.模型调用(预测)#TODO参考资料https://github.com/qfgaohao/pytorch-ssd
-
python使用opencv读取海康摄像头视频流rtsp pythons使用opencv读取海康摄像头视频流rtsp海康IPcamera rtsp地址和格式:rtsp://[username]:[password]@[ip]:[port]/[codec]/[channel]/[subtype]/av_stream 说明: username: 用户名。例如admin。 password: 密码。例如12345。 ip: 为设备IP。例如 192.0.0.64。 port: 端口号默认为554,若为默认可不填写。 codec:有h264、MPEG-4、mpeg4这几种。 channel: 通道号,起始为1。例如通道1,则为ch1。 subtype: 码流类型,主码流为main,辅码流为sub。python读取视频流import cv2 url = 'rtsp://admin:!itrb123@10.1.9.143:554/h264/ch1/main/av_stream' cap = cv2.VideoCapture(url) while(cap.isOpened()): # Capture frame-by-frame ret, frame = cap.read() # Display the resulting frame cv2.imshow('frame',frame) if cv2.waitKey(1) & 0xFF == ord('q'): break # When everything done, release the capture cap.release() cv2.destroyAllWindows()
-
Pytorch 实战:使用Resnet18实现对是否戴口罩进行图片分类 1.实验环境torch = 1.6.0torchvision = 0.7.0matplotlib = 3.3.3 # 绘图用progressbar = 2.5 # 绘制进度条用easydict # 超参数字典功能增强2.数据集数据集介绍包含2582张图片,3个类别(yes/unknow/no)下载地址:口罩检测数据集3.导入相关的包# 导包 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader import torchvision from torchvision import datasets,transforms import matplotlib.pyplot as plt import random from progressbar import *4.设置超参数# 定义超参数 from easydict import EasyDict super_param={ 'train_data_root' : './data/train', 'val_data_root' : './data/train', 'device': torch.device('cuda:0' if torch.cuda.is_available() else cpu), 'lr': 0.001, 'epochs': 3, 'batch_size': 1, 'begain_epoch':0, 'model_load_flag':False, #是否加载以前的模型 'model_load_path':'./model/resnet18/epoch_1_0.8861347792408986.pkl', 'model_save_dir':'./model/resnet18', } super_param = EasyDict(super_param) if not os.path.exists(super_param.model_save_dir): os.mkdir(super_param.model_save_dir)5.模型搭建# 模型搭建,调用预训练模型Resnet18 class Modified_Resnet18(nn.Module): """docstring for ClassName""" def __init__(self, num_classs=3): super(Modified_Resnet18, self).__init__() model = torchvision.models.resnet18(pretrained=True) model.fc = nn.Linear(model.fc.in_features,num_classs) self.model = model def forward(self, x): x = self.model(x) return x model = Modified_Resnet18() print(model)Modified_Resnet18( (model): ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer3): Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer4): Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=512, out_features=3, bias=True) ) )6.加载数据集# 训练数据封装成dataloader # 定义数据处理的transform transform = transforms.Compose([ transforms.Resize((224,224)), transforms.ToTensor(), # 0-255 to 0-1 # transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), ]) train_dataset =torchvision.datasets.ImageFolder(root=super_param.train_data_root,transform=transform) train_loader =DataLoader(train_dataset,batch_size=super_param.batch_size, shuffle=True) val_dataset =torchvision.datasets.ImageFolder(root=super_param.val_data_root,transform=transform) val_loader =DataLoader(val_dataset,batch_size=super_param.batch_size, shuffle=True) # 保存类别与类别索引的对应关系 class_to_idx = train_dataset.class_to_idx idx_to_class = dict([val,key] for key,val in class_to_idx.items()) print(len(train_dataset),len(val_dataset))查看一个数据样例#查看一个数据 import matplotlib.pyplot as plt index = random.randint(0,len(val_dataset)) img,idx = val_dataset[index] img = img.permute(1,2,0) label = idx_to_class[idx] print("label=",label) plt.figure(dpi=100) plt.xticks([]) plt.yticks([]) plt.imshow(img) plt.show()7.定义损失函数和优化器# 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(),lr=super_param.lr)8.定义单个epoch的训练函数# 定义单个epoch的训练函数 def train_epoch(model,train_loader,super_param,criterion,optimizer,epoch): model.train()#训练声明 for batch_index,(imgs,labels) in enumerate(train_loader): #data上device imgs,labels = imgs.to(super_param.device),labels.to(super_param.device) #梯度清零 optimizer.zero_grad() #前向传播 output = model(imgs) #损失计算 loss = criterion(output,labels) #梯度计算,反向传播 loss.backward() #参数优化 optimizer.step() #打印参考信息 if(batch_index % 10 == 0): print("\rEpoch:{} Batch Index(batch_size={}):{}/{} Loss:{}".format(epoch,super_param.batch_size,batch_index,len(train_loader),loss.item()),end="")9.定义验证函数# 定义验证函数 def val(model,val_loader,super_param,criterion): model.eval()#测试声明 correct = 0.0 #正确数量 val_loss = 0.0 #测试损失 #定义进度条 widgets = ['Val: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=100).start() with torch.no_grad(): # 不会计算梯度,也不会进行反向传播 for batch_index,(imgs,labels) in enumerate(val_loader): imgs,labels = imgs.to(super_param.device),labels.to(super_param.device) output = model(imgs)#模型预测 val_loss += criterion(output,labels).item() # 计算测试损失 #argmax返回 值,索引 dim=1表示要索引 pred = output.argmax(dim=1) # 找到概率最大的下标 correct += pred.eq(labels.view_as(pred)).sum().item()# 统计预测正确数量 # print("pred===========",pred) pbar.update(batch_index/len(val_loader)*100)#更新进度条进度 #释放进度条 pbar.finish() val_loss /= len(val_loader.dataset) val_accuracy = correct / len(val_loader.dataset) time.sleep(0.01) print("Val --- Avg Loss:{},Accuracy:{}".format(val_loss,val_accuracy)) return val_loss,val_accuracy10.模型训练model = model.to(super_param.device) if super_param.model_load_flag: #加载训练过的模型 model.load_state_dict(torch.load(super_param.model_load_path)) # 数据统计-用于绘图和模型保存 epoch_list = [] loss_list = [] accuracy_list =[] best_accuracy = 0.0 for epoch in range(super_param.begain_epoch,super_param.begain_epoch+super_param.epochs): train_epoch(model,train_loader,super_param,criterion,optimizer,epoch) val_loss,val_accuracy = val(model,val_loader,super_param,criterion) #数据统计 epoch_list.append(epoch) loss_list.append(val_loss) accuracy_list.append(accuracy_list) #保存准确率更高的模型 if(val_accuracy>best_accuracy): best_accuracy = val_accuracy torch.save(model.state_dict(),os.path.join(super_param.model_save_dir, 'epoch_' + str(epoch)+ '_' + str(best_accuracy) + '.pkl')) print('epoch_' + str(epoch) + '_' + str(best_accuracy) + '.pkl'+"保存成功")11.查看数据统计结果# 查看数据统计结果 fig = plt.figure(figsize=(12,12),dpi=70) #子图1 ax1 = plt.subplot(2,1,1) title = "bach_size={},lr={}".format(super_param.batch_size,super_param.lr) plt.title(title,fontsize=15) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Loss',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,loss_list) #子图2 ax2 = plt.subplot(2,1,2) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Accuracy',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,accuracy_list,'r') plt.show()
-
python实现音频读取与可视化+端点检测+音频切分 1.音频读取与可视化1.1 核心代码import wave import matplotlib.pyplot as plt import numpy as np import os filepath = "./audio/day0716_17.wav" f = wave.open(filepath,'rb') # 读取音频 params = f.getparams() # 查看音频的参数信息 print(params) # 可视化准备工作 strData = f.readframes(nframes)#读取音频,字符串格式 waveData = np.fromstring(strData,dtype=np.int16)#将字符串转化为int waveData = waveData*1.0/(max(abs(waveData)))#wave幅值归一化 # 可视化 time = np.arange(0,nframes)*(1.0 / framerate) plt.figure(figsize=(20,4)) plt.plot(time,waveData) plt.xlabel("Time(s)") plt.ylabel("Amplitude") plt.title("Single channel wavedata") plt.grid('on')#标尺,on:有,off:无。1.2 实现效果_wave_params(nchannels=1, sampwidth=2, framerate=16000, nframes=8744750, comptype='NONE', compname='not compressed')2.端点检测2.1 环境准备pip install speechbrain2.2 核心代码from speechbrain.pretrained import VAD VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty") boundaries = VAD.get_speech_segments("./day0716_17.wav") print(boundaries)2.3 输出结果输出结果为包含语音数据的[开始时间,结束时间]区间序列tensor([[ 1.1100, 4.5700], [ 5.5600, 7.6100], [ 8.5800, 12.7800], ······ [508.7500, 519.0300], [526.0800, 537.1100], [538.0200, 546.5200]])3.pydub分割并保存音频3.1 核心代码from pydub import AudioSegment file_name = "denoise_0306.wav" sound = AudioSegment.from_mp3(file_name) # 单位:ms crop_audio = sound[1550:1900] save_name = "crop_"+file_name print(save_name) crop_audio.export(save_name, format="wav",tags={'artist': 'AppLeU0', 'album': save_name})4.汇总(仅供参考)汇总方式自行编写。以下案例为处理audio文件夹的的所有的wav结尾的文件从中提取出有声音的片段并进保存到相应的文件夹from pydub import AudioSegment import os from speechbrain.pretrained import VAD VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty") audio_dir = "./audio/" audio_name_list = os.listdir(audio_dir) for audio_name in audio_name_list: if not audio_name.endswith(".wav"): continue print(audio_name,"开始处理") audio_path = os.path.join(audio_dir,audio_name) word_save_dir = os.path.join(audio_dir,audio_name[:-4]) if not os.path.exists(word_save_dir): os.mkdir(word_save_dir) else: print(audio_name,"已经完成,跳过") continue boundaries = VAD.get_speech_segments(audio_path) sound = AudioSegment.from_mp3(audio_path) for boundary in boundaries: start_time = boundary[0] * 1000 end_time = boundary[1] * 1000 word = sound[start_time:end_time] word_save_path = os.path.join(word_save_dir,str(int(boundary[0]))+"-"+ str(int(boundary[1])) +".wav") word.export(word_save_path, format="wav") print("\r"+word_save_path,"保存成功",end="") print(audio_name,"处理完成")参考资料https://huggingface.co/speechbrain/vad-crdnn-libripartypydub分割并保存音频
-
快速使用Yolov4-tiny训练VOC格式的数据集 1.训练步骤STEP1:下载代码并配置环境git clone https://github.com/bubbliiiing/yolov4-tiny-pytorch.git cd yolov4-tiny-pytorch pip install -r requirements.txtSTEP2:根据文件结构填充VOC格式的数据集数据放置格式(只需完成#TODO部分即可)├──VOCdevkit/VOC2007/ ├── Annotations #可以采用软连接的方式避免对大量数据进行复制 ├──放置xml文件 #TODO ├── JPEGImages ├──放置img文件 #TODO ├──ImageSets/Main #可以采用软连接的方式避免对大量数据进行复制 ├──放置训练索引文件 (无需手动完成,自动生成) ├── voc2yolo.py #数据分割脚本,用于生成训练索引文件编辑voc2yolo.py。设置tarin\val\test数据分割比例#----------------------------------------------------------------------# # 验证集的划分在train.py代码里面进行 # test.txt和val.txt里面没有内容是正常的。训练不会使用到。 #----------------------------------------------------------------------# ''' #--------------------------------注意----------------------------------# 如果在pycharm中运行时提示: FileNotFoundError: [WinError 3] 系统找不到指定的路径。: './VOCdevkit/VOC2007/Annotations' 这是pycharm运行目录的问题,最简单的方法是将该文件复制到根目录后运行。 可以查询一下相对目录和根目录的概念。在VSCODE中没有这个问题。 #--------------------------------注意----------------------------------# ''' import os import random random.seed(0) xmlfilepath=r'./Annotations' saveBasePath=r"./ImageSets/Main/" #----------------------------------------------------------------------# # 想要增加测试集修改trainval_percent # train_percent不需要修改 #----------------------------------------------------------------------# trainval_percent=0.9 train_percent=1 temp_xml = os.listdir(xmlfilepath) total_xml = [] for xml in temp_xml: if xml.endswith(".xml"): total_xml.append(xml) num=len(total_xml) list=range(num) tv=int(num*trainval_percent) tr=int(tv*train_percent) trainval= random.sample(list,tv) train=random.sample(trainval,tr) print("train and val size",tv) print("traub suze",tr) ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w') ftest = open(os.path.join(saveBasePath,'test.txt'), 'w') ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w') fval = open(os.path.join(saveBasePath,'val.txt'), 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest .close()生成训练索引文件python voc2yolo.pySTEP3:对VOC数据集将进行类别统计├──VOCdevkit/VOC2007/ ├── get_all_class.py #VOC类别统计脚本在其中写入以下内容import xmltodict import os # VOC xml文件所在文件夹 annotation_dir="./Annotations/" label_list = list() # 逐一处理xml文件 for file in os.listdir(annotation_dir): annotation_path = os.path.join(annotation_dir,file) # 读取xml文件 with open(annotation_path,'r') as f: xml_str = f.read() #转为字典 xml_dic = xmltodict.parse(xml_str) # 获取label并去重加入到label_list objects = xml_dic["annotation"]["object"] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: label = obj['name'] if label not in label_list: label_list.append(label) else:# xml文件中只包含1个object obj = objects label = obj['name'] if label not in label_list: label_list.append(label) print(label_list)然后运行get_all_class.py获取所有的类别信息['Person', 'BridgeVehicle', 'LuggageVehicle', 'Plane', 'RefuelVehicle', 'FoodVehicle', 'RubbishVehicle', 'WaterVehicle', 'PlatformVehicle', 'TractorVehicle', 'BridgeConnector']STEP4:编辑model_data/voc_classes.txt 和下载权重文件将其中的类别数改为自己的,文件内容为Person BridgeVehicle LuggageVehicle Plane RefuelVehicle FoodVehicle RubbishVehicle WaterVehicle PlatformVehicle TractorVehicle BridgeConnector下载权重文件到model_data文件夹下wget https://github.com/bubbliiiing/yolov4-tiny-pytorch/releases/download/v1.0/yolov4_tiny_weights_coco.pthSTEP4:生成最终训练所需的txt文件然后运行voc_annotation.pypython voc_annotation.py此时会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。STEP5:修改train.py的NUM_CLASSSES将train.py的NUM_CLASSSES修改成所需要分的类的个数(不需要+1)STEP6:开始训练python train.py2.模型预测在yolo.py文件里面,在如下部分修改model_path和classes_path使其对应训练好的文件;model_path对应logs文件夹下面的权值文件,classes_path是model_path对应分的类。_defaults = { #--------------------------------------------------------------------------# # 使用自己训练好的模型进行预测一定要修改model_path和classes_path! # model_path指向logs文件夹下的权值文件,classes_path指向model_data下的txt # 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改 #--------------------------------------------------------------------------# "model_path" : 'model_data/yolov4_tiny_weights_coco.pth', "classes_path" : 'model_data/coco_classes.txt', #---------------------------------------------------------------------# # anchors_path代表先验框对应的txt文件,一般不修改。 # anchors_mask用于帮助代码找到对应的先验框,一般不修改。 #---------------------------------------------------------------------# "anchors_path" : 'model_data/yolo_anchors.txt', "anchors_mask" : [[3,4,5], [1,2,3]], #-------------------------------# # 所使用的注意力机制的类型 # phi = 0为不使用注意力机制 # phi = 1为SE # phi = 2为CBAM # phi = 3为ECA #-------------------------------# "phi" : 0, #---------------------------------------------------------------------# # 输入图片的大小,必须为32的倍数。 #---------------------------------------------------------------------# "input_shape" : [416, 416], #---------------------------------------------------------------------# # 只有得分大于置信度的预测框会被保留下来 #---------------------------------------------------------------------# "confidence" : 0.5, #---------------------------------------------------------------------# # 非极大抑制所用到的nms_iou大小 #---------------------------------------------------------------------# "nms_iou" : 0.3, #---------------------------------------------------------------------# # 该变量用于控制是否使用letterbox_image对输入图像进行不失真的resize, # 在多次测试后,发现关闭letterbox_image直接resize的效果更好 #---------------------------------------------------------------------# "letterbox_image" : False, #-------------------------------# # 是否使用Cuda # 没有GPU可以设置成False #-------------------------------# "cuda" : True, }运行predict.py,输入待测试的图片路径img/street.jpg在predict.py里面进行设置可以进行fps测试和video视频检测。3.评估自己的数据集前往get_map.py文件修改classes_path,classes_path用于指向检测类别所对应的txt,这个txt和训练时的txt一样。评估自己的数据集必须要修改。在yolo.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。参考资料https://github.com/bubbliiiing/yolov4-tiny-pytorch
-
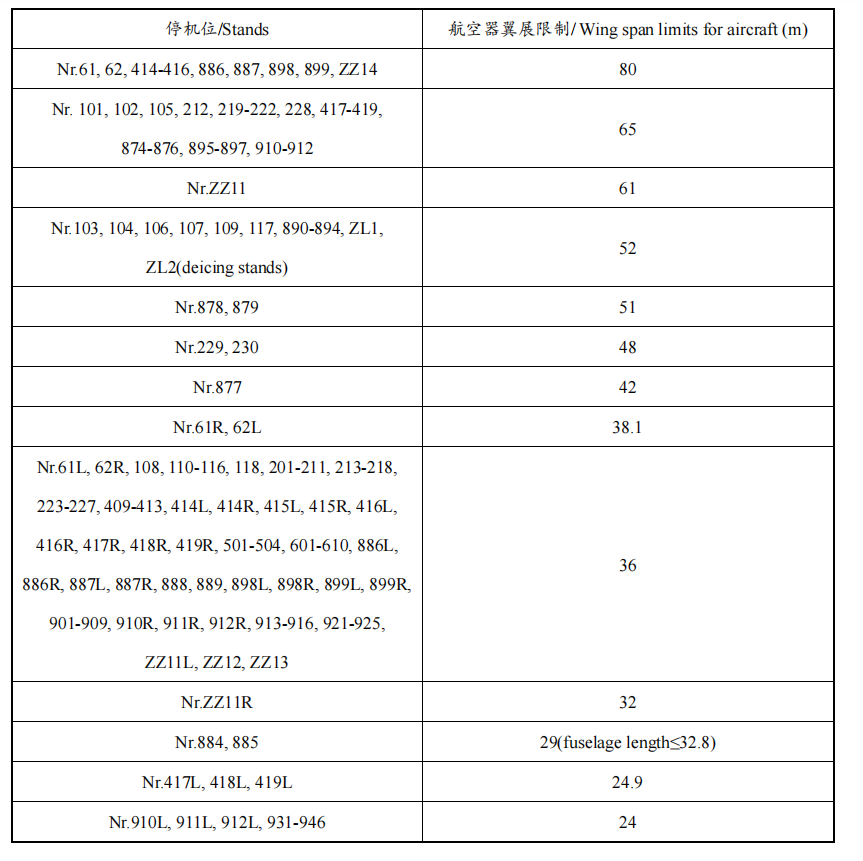
python结合opencv调用谷歌tesseract-ocr实现印刷体的表格识别识别 环境搭建安装依赖-leptonica库下载源码git clone https://github.com/DanBloomberg/leptonica.gitconfiguresudo apt install automake bash autogen.sh ./configure编译安装make sudo make install这样就安装好了leptonica库谷歌tesseract-ocr编译安装下载源码git clone https://github.com/tesseract-ocr/tesseract.git tesseract-ocr安装依赖sudo apt-get install g++ autoconf automake libtool autoconf-archive pkg-config libpng12-dev libjpeg8-dev libtiff5-dev zlib1g-dev libleptonica-dev -y安装训练所需要的库(只是调用可以不用安装)sudo apt-get install libicu-dev libpango1.0-dev libcairo2-devconfigurebash autogen.sh ./configure编译安装make sudo make install # 可选项,不训练可以选择不执行下面两条 make training sudo make training-install sudo ldconfig安装对应的字体库并添加对应的环境变量下载好的语言包 放在/usr/local/share/tessdata目录里面。语言包地址:https://github.com/tesseract-ocr/tessdata_best。里面有各种语言包,都是训练好的语言包。简体中文下载:chi_sim.traineddata , chi_sim_vert.traineddata英文包:eng.traineddata。设置环境变量vim ~/.bashrc # 在.bashrc的文件末尾加入以下内容 export TESSDATA_PREFIX=/usr/local/share/tessdata source ~/.bashrc查看字体库tesseract --list-langs使用tesseract-ocr测试# 识别/home/app/1.png这张图片,内容输出到output.txt 里面,用chi_sim 中文来识别(不用加.traineddata,会默认加) tesseract /home/app/1.png output -l chi_sim # 查看识别结果 cat output.txt安装python调用依赖包pip install pytesseract配合opencv调用进行印刷体表格识别代码import cv2 import numpy as np import pytesseract import matplotlib.pyplot as plt import re #原图 raw = cv2.imread("table3.2.PNG") # 灰度图片 gray = cv2.cvtColor(raw, cv2.COLOR_BGR2GRAY) # 二值化 binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5) rows, cols = binary.shape # 识别横线 scale = 50 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (cols // scale, 1)) eroded = cv2.erode(binary, kernel, iterations=1) dilated_col = cv2.dilate(eroded, kernel, iterations=1) # 识别竖线 scale = 10 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, rows // scale)) eroded = cv2.erode(binary, kernel, iterations=1) dilated_row = cv2.dilate(eroded, kernel, iterations=1) # 标识交点 bitwise_and = cv2.bitwise_and(dilated_col, dilated_row) plt.figure(dpi=300) # plt.imshow(bitwise_and,cmap="gray") # 标识表格 merge = cv2.add(dilated_col, dilated_row) plt.figure(dpi=300) # plt.imshow(merge,cmap="gray") # 两张图片进行减法运算,去掉表格框线 merge2 = cv2.subtract(binary, merge) plt.figure(dpi=300) # plt.imshow(merge2,cmap="gray") # 识别黑白图中的白色交叉点,将横纵坐标取出 ys, xs = np.where(bitwise_and > 0) # 提取单元格切分点 # 横坐标 x_point_arr = [] # 通过排序,获取跳变的x和y的值,说明是交点,否则交点会有好多像素值值相近,我只取相近值的最后一点 # 这个10的跳变不是固定的,根据不同的图片会有微调,基本上为单元格表格的高度(y坐标跳变)和长度(x坐标跳变) sort_x_point = np.sort(xs) for i in range(len(sort_x_point) - 1): if sort_x_point[i + 1] - sort_x_point[i] > 10: x_point_arr.append(sort_x_point[i]) i = i + 1 x_point_arr.append(sort_x_point[i]) # 要将最后一个点加入 # 纵坐标 y_point_arr = [] sort_y_point = np.sort(ys) for i in range(len(sort_y_point) - 1): if (sort_y_point[i + 1] - sort_y_point[i] > 10): y_point_arr.append(sort_y_point[i]) i = i + 1 # 要将最后一个点加入 y_point_arr.append(sort_y_point[i]) # 循环y坐标,x坐标分割表格 plt.figure(dpi=300) data = [[] for i in range(len(y_point_arr))] for i in range(len(y_point_arr) - 1): for j in range(len(x_point_arr) - 1): # 在分割时,第一个参数为y坐标,第二个参数为x坐标 cell = raw[y_point_arr[i]:y_point_arr[i + 1], x_point_arr[j]:x_point_arr[j + 1]] #读取文字,此为默认英文 text1 = pytesseract.image_to_string(cell, lang="chi_sim+eng") #去除特殊字符 text1 = re.findall(r'[^\*"/:?\\|<>″′‖ 〈\n]', text1, re.S) text1 = "".join(text1) print('单元格图片信息:' + text1) data[i].append(text1) plt.subplot(len(y_point_arr),len(x_point_arr),len(x_point_arr)*i+j+1) plt.imshow(cell) plt.axis('off') plt.tight_layout() plt.show()实现效果表格图片识别结果单元格图片信息:停机位Stands 单元格图片信息:空器避展限制Wingspanlimitsforaircraft(m) 单元格图片信息:Nr61.62.414-416.886.887.898,899.ZZ14 单元格图片信息:80 单元格图片信息:Nr101,102.105,212.219-222,228.417-419,874-876.895-897.910-912 单元格图片信息:65 单元格图片信息:NrZZ11 单元格图片信息:61 单元格图片信息:Nr103,104.106.107.109,117,890-894.ZL1,ZL2(deicingstands) 单元格图片信息:52 单元格图片信息:Nr878.879 单元格图片信息:51 单元格图片信息:Nr229.230 单元格图片信息:48 单元格图片信息:Nr877 单元格图片信息:42 单元格图片信息:Nr61R.62L 单元格图片信息:38.1 单元格图片信息:Nr61L.62R.108.110-116,118.201-211.213-218,223-227.409-413,414L.414R.415L.415R.416L,416R.417R.418R.419R.501-504.601-610,886L,886R.887L.887R.888.889.898L.898R.8991L.899R_901-909,910R.911R.912R.913-916.921-925.ZZ1IL.ZZ12.ZZ13 单元格图片信息:36 单元格图片信息:NrZZ11IR 单元格图片信息:32 单元格图片信息:Nr884.885 单元格图片信息:29(fuselagelength32.8) 单元格图片信息:Nr417L.418L.419L 单元格图片信息:24.9 单元格图片信息:Nr910L.911L.912L.931-946 单元格图片信息:24
-
使用python+opencv快速实现画风迁移效果 风格类型模型风格(翻译可能有误)candy糖果composition_vii康丁斯基的抽象派绘画风格feathers羽毛udnie乌迪妮la_muse缪斯mosaic镶嵌the_wave海浪starry_night星夜the_scream爱德华·蒙克创作绘画风格(呐喊)模型下载脚本BASE_URL="http://cs.stanford.edu/people/jcjohns/fast-neural-style/models/" mkdir -p models/instance_norm cd models/instance_norm curl -O "$BASE_URL/instance_norm/candy.t7" curl -O "$BASE_URL/instance_norm/la_muse.t7" curl -O "$BASE_URL/instance_norm/mosaic.t7" curl -O "$BASE_URL/instance_norm/feathers.t7" curl -O "$BASE_URL/instance_norm/the_scream.t7" curl -O "$BASE_URL/instance_norm/udnie.t7" mkdir -p ../eccv16 cd ../eccv16 curl -O "$BASE_URL/eccv16/the_wave.t7" curl -O "$BASE_URL/eccv16/starry_night.t7" curl -O "$BASE_URL/eccv16/la_muse.t7" curl -O "$BASE_URL/eccv16/composition_vii.t7" cd ../../代码调用import cv2 import matplotlib.pyplot as plt import os # 定义调用模型进行风格迁移的函数 def convert_img(model_path,img): # 加载模型 net = cv2.dnn.readNetFromTorch(model_path) net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV) #设置后端 # 从图像中创建四维连通区域 w,h,_ = img.shape blob = cv2.dnn.blobFromImage(img,1.0,(h,w)) # 图片流经模型 net.setInput(blob) out = net.forward() # 模型输出修正 out = out.reshape(3,out.shape[2],out.shape[3]) out = out.transpose(1,2,0) out = out/255.0 return out # 读取图片 img = cv2.imread("./img/img2.jpg") # 调用模型进行风格迁移 out = convert_img("./model/feathers.t7",img) # 模型效果展示 plt.figure(dpi=200) plt.subplot(1,2,1) plt.title("origin") plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.subplot(1,2,2) plt.title("feathers") plt.imshow(cv2.cvtColor(out, cv2.COLOR_BGR2RGB)) plt.show()实现效果参考资料OpenCV4学习笔记(69)——dnn模块之基于fast_style模型实现快速图像风格迁移
-
图像padding为正方形并绘制网格(python+opencv实现) 代码实现import matplotlib.pyplot as plt import cv2 import numpy as np img = cv2.imread("./demo.jpg") """ 图像padding为正方形 """ def square_img(img_cv): # 获取图像的宽高 img_h,img_w = img_cv.shape[0:2] # 计算padding值并将图像padding为正方形 padw,padh = 0,0 if img_h>img_w: padw = (img_h - img_w) // 2 img_pad = np.pad(img_cv,((0,0),(padw,padw),(0,0)),'constant',constant_values=0) elif img_w>img_h: padh = (img_w - img_h) // 2 img_pad = np.pad(img_cv,((padh,padh),(0,0),(0,0)), 'constant', constant_values=0) return img_pad """ 在图像上绘制网格 核心函数 cv2.line(img, (start_x, start_y), (end_x, end_y), (255, 0, 0), 1, 1) """ def draw_grid(img,grid_x,grid_y,line_width=5): img_x,img_y = img.shape[:2] # 绘平行y方向的直线 dx = int(img_x/grid_x) for i in range(0,img_x,dx): cv2.line(img, (i, 0), (i, img_y), (255, 0, 0), line_width) # 绘平行x方向的直线 dy = int(img_y/grid_y) for i in range(0,img_x,dx): cv2.line(img, (0, i), (img_x, i), (255, 0, 0), line_width) return img img = square_img(img) img = draw_grid(img,20,20) # 20,20为网格的shape img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(img) plt.show()调用效果代码参数需要稍作修改才能得到如下全部效果
-
-
linux下快速安装cmake步骤详解 安装步骤1.获cmake快速安装脚本下载地址https://cmake.org/download/下载对应系统.sh后缀的文件# 创建并进入软件安装目录 mkdir software && cd $_ # 下载快速安装脚本 wget https://github.com/Kitware/CMake/releases/download/v3.21.4/cmake-3.21.4-linux-x86_64.sh2.运行快速安装脚本安装bash cmake-3.21.4-linux-x86_64.sh3.配置环境变量vim ~/.bashrc # 在文件末尾加上这个--根据自己的实际安装路径填写 export PATH="$PATH:/home/admin/software/cmake-3.21.4-linux-x86_64/bin" # 激活环境变量 source ~/.bashrc4.验证是否安装成功$ cmake --version cmake version 3.21.4 CMake suite maintained and supported by Kitware (kitware.com/cmake).
-
python学习:正则表达式re模块的使用 1.常用常量1.1 re.I(re.IGNORECASE)执行不区分大小写的匹配;类似的表达式也[A-Z]将匹配小写字母。re.findall(r"[a-z]", "ah667GHD67DYT78") # Return:['a', 'h'] re.findall(r"[a-z]", "ah667GHD67DYT78",flags=re.IGNORECASE) # Return:['a', 'h', 'G', 'H', 'D', 'D', 'Y', 'T']1.2 re.S(re.DOTALL)使'.'特殊字符与任何字符都匹配,包括换行符;没有此标志,'.'将匹配除换行符以外的任何内容。s = '''first line second line third line''' re.findall(r".+", s) # Return:['first line', 'second line', 'third line'] re.findall(r".+", s, flags=re.DOTALL) # Return:['first line\nsecond line\nthird line']2.常用方法2.1 re.match(pattern,string,flags = 0 )对字符串从开头进行正则匹配 (匹配零个或者一个对象)如果字符串与模式匹配,则返回相应的匹配对象。re.match('a','abcade') # Return:<re.Match object; span=(0, 1), match='a'> re.match('\w+','abc123de') # Return:<re.Match object; span=(0, 8), match='abc123de'>如果字符串与模式不匹配,则返回None;re.match('z','abcade') # Return:None可以使用group()获取匹配结果re.match('a','abcade').group() # Return:'a'2.2 re.search(pattern,string,flags = 0 )扫描字符串以查找正则表达式模式产生匹配项的第一个位置(匹配零个或者一个对象),与re.match的区别re.match是从字符串的开头进行匹配re.search是从对字符串的挨个位置都进行尝试,指导匹配上或者尝试完所有位置如果匹配上,则返回相应的match对象。re.search('b','abcade') # Return:<re.Match object; span=(1, 2), match='b'> re.search('b','abcade').group() # Return:'b'如果字符串中没有位置与模式匹配,则返回None;re.search('z','abcade') # Return:None2.3 re.compile(pattern,flags = 0 )该方法同re.match和re.search将正则表达式模式编译为正则表达式对象,可使用match(),search()以及下面所述的其他方法将其用于匹配reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.search('12abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.search('12abc').group() # Return:12reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.match('123abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.match('12abc').group() # Return:122.4 re.fullmatch(pattern,string,flags = 0 )如果整个字符串与正则表达式模式匹配,则返回相应的match对象。re.fullmatch('\w+','abcade') # Return:<re.Match object; span=(0, 6), match='abcade'> re.fullmatch('\w+','abcade').group() # Return:'abcade'否则返回None;re.fullmatch('\w+','abca de') # Return:None2.5 re.split(pattern,string,maxsplit = 0,flags = 0 )通过正则表达式来split字符串。re.split(r'\W+', 'Words, words, words.') # Return:['Words', 'words', 'words', '']如果在pattern中使用了捕获括号,那么模式中所有组的文本也将作为结果列表的一部分返回。re.split(r'(\W+)', 'Words, words, words.') # Return:['Words', ', ', 'words', ', ', 'words', '.', '']如果分隔符中有捕获组,并且该匹配组在字符串的开头匹配,则结果将从空字符串开始。字符串的末尾也是如此:re.split(r'(\W+)', '...words, words...') # Return:['', '...', 'words', ', ', 'words', '...', '']如果maxsplit不为零,则最多会发生maxsplit分割,并将字符串的其余部分作为列表的最后一个元素返回。re.split(r'\W+', 'Words, words, words.',1) # Return:['Words', 'words, words.']2.6 re.findall(pattern,string,flags = 0 )从左到右扫描该字符串,以列表的形式返回所有的匹配项re.findall('a', 'This is a beautiful place!') # Return:['a', 'a', 'a'] re.findall('z', 'This is a beautiful place!') # Return:[]2.7 re.sub(pattern,repl,string,count = 0,flags = 0 )使用repl替换掉string中pattern成功匹配的匹配项,count参数表示将匹配到的内容进行替换的次数re.sub('\d', 'S', 'abc12jh45li78') #将匹配到所有的数字替换成S # Return:'abcSSjhSSliSS' re.sub('\d', 'S', 'abc12jh45li78', 2) #将匹配到的数字替换成S,只替换2次就停止 # Return:'abcSSjh45li78'如果找不到该模式, 则返回的字符串不变。re.sub('z', 'S', 'abc12jh45li78') # Return:'abc12jh45li78'2.8 re.subn(pattern,repl,string,count = 0,flags = 0 )执行与相同的操作sub(),但返回一个元组。(new_string, number_of_subs_made)re.subn('\d', 'S', 'abc12jh45li78') # Return:('abcSSjhSSliSS', 6) re.subn('\d', 'S', 'abc12jh45li78', 3) # Return:('abcSSjhS5li78', 3)3. 其他补充3.1 使用正则表达式匹配中文 re.findall(r"[\u4e00-\u9fa5]", "沿charlie在charlie五前等待。charlie charlie五前等四川八八六四") # Return:['沿', '在', '五', '前', '等', '待', '五', '前', '等', '四', '川', '八', '八', '六', '四']3.2 贪心匹配和非贪心匹配贪心匹配:正则表达式在有二义的情况下,会尽可能匹配最长的字符串Python的正则表达式默认是”贪心“的,这表示在有二义的情况下,会尽可能匹配最长的字符串。re.search(r'(ha){3,5}','hahahahaha').group() # Return:'hahahahaha'非贪心匹配:匹配尽可能最短的字符串使用方式:在有二义的正则表达式的后面跟一个问号re.search(r'(ha){3,5}?','hahahahaha').group() # Return:'hahaha'参考资料使用正则表达式Python之re模块python 正则表达式详解